
A Rule-Driven Approach to Data Validation
In our previous blog post we discussed a high level approach to Automated Data Validation Using FME and mentioned that a key component of that architecture was the rules DB – a database containing the data validation rules. This post expands on that idea and provides a basic framework that can be applied to authoring data validation workspaces using FME that are as simple and generic as possible, yet still provide a powerful validation solution that can be applied in a multitude of scenarios.
Traditionally, when approaching the problem of data validation using FME, many workspace authors will take the logical approach that is common to solving so many of our data challenges: read in source data; apply processing rules using a combination of filters and transformations in the workspace; then write out the results. Taking this approach, the FME workspace can quickly grow to be large and complex, with embedded logic and data paths for each validation rule. Additionally, if validation rules are added, changed or removed, the workspace needs to be updated accordingly.
Even with judicious use of bookmarks, annotations and custom transformers to clean up the workspace, things can quickly become unmanageable as this partial view of an existing workspace illustrates.
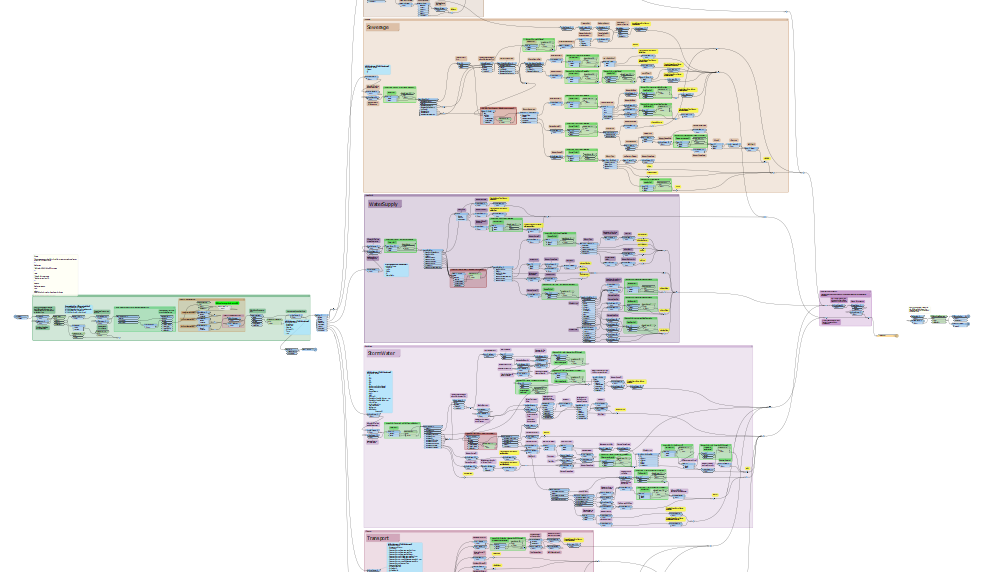
By abstracting the validation rules out to an external repository (rules database), we can keep the FME workspace concise, simple and easy to maintain.
Benefits of the Rule-Driven Approach
The idea behind using a database** to define the validation rules is that the FME workspace can be kept as simple and generic as possible. The benefit of this approach is that updates to validation rules do not generally require modifications to the FME workspace, leading to:
Validation rules can be defined and edited by business users and subject matter experts who may not have the technical skills to update an FME workspace;
Reduced ongoing workspace maintenance (as the validation rules are stored externally), leading to reduced cost and the ability for sparse FME technical resources to focus on other work;
Reduced complexity of the FME workspace, meaning, if workspace updates are required for some reason, the logic should be simple to follow and easy to understand, once again leading to reduced development time and cost.
** NOTE:
Before we go any further, it’s worth pointing out that, although we will continually be referring to a rules “database”, in reality, the database can be any type of file or true DB that can maintain a logical set of rules. Commonly, this is often a simple CSV or Excel spreadsheet or cloud-hosted online document.
Rule-Driven Validation
Typically, the types of validation that need to be performed can be broken down into three main categories that can be easily managed using a rules DB approach:
Schema Validation
Data Validation
Spatial Validation
There may be other, more complex or custom validations required for a given dataset, in which case some level of custom FME workspace development may be required but the majority of validation can be categorised into one of the above types and handled with a generic validation approach.
Schema Validation
Schema validation refers to a very high-level initial validation that the incoming features are of an expected type. Commonly, this might simply require validation of incoming feature names and geometry types (e.g. File GeoDatabase feature class name and geometry type) to ensure that only expected feature types are processed. If an unexpected feature type is encountered in the source data it can be rejected, or simply ignored.
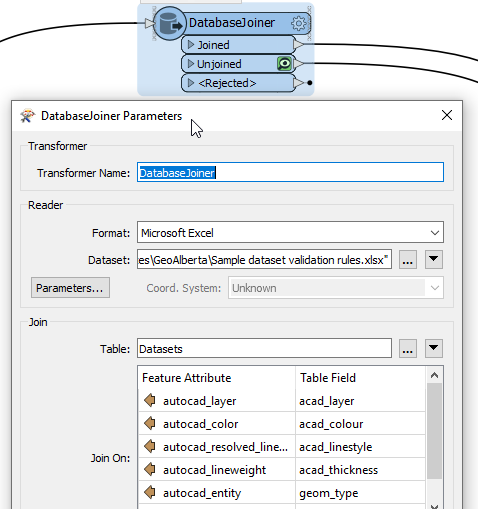
In the case of source data in CAD format additional combinations of schema information can be defined, as illustrated in the following screenshot:

The schema validation rules can also define a mapping to a target feature type. In the above example, the CAD layer name, colour, linestyle, etc. are mapped to their respective target SDE Feature Class name.
In FME, the schemas are easily validated using a simple DatabaseJoiner to determine which incoming features match a definition in the rules DB:
Data Validation
Data validation verifies that attributes contain expected values. This might be as simple as validating that they conform to expected data types (e.g. text, number, date, etc.) and length/precision, or there may be more specific data content rules to be validated.

Data content rule types are defined in the example rules DB, above, by a “validation_type” entry and each validation type will be defined in the FME workspace as a custom transformer, with validation-specific details supplied in the “rule” column.
Attributes can also be defined as required/optional and default values can be defined in the rules DB, in case the value is empty on the incoming data.
An example FME implementation might look something like the following (error handling logic has been omitted for clarity):

As with the schema validation rules, target schema attribute names could be defined in the rules DB and the source to target name mappings would be automatically handled by the workspace.
Spatial Validation
Spatial validation evaluates topological relationships between features. As shown in this example, the topological relationships can only be between two feature types – relationships between multiple feature types is not supported and would likely require custom FME workspace development.
There are two types of spatial relationship definition supported: named relationships (e.g. WITHIN, EQUALS, DISJOINT, TOUCHES, CONTAINS, INTERSECTS) and 9-character masks (e.g. “T*F**F***” [within]).

The topological relationship may be further qualified by specifying attributes which must have values which match/differ for each feature.
This validation is accomplished in the FME workspace using a simple SpatialRelator or SpatialFilter transformer.

Wrapping the SpatialRelator/Filter into a custom transformer allows for the handling of transformer parameter values driven by the rules DB definition:

Rules DB Limitations
The rules DB approach to schema validation is powerful and convenient but does have some limitations:
Complex validation rules, evaluating the relationship between multiple feature types/attributes, are not supported and need to be custom coded in the FME workspace.
“Whole dataset” rules are not supported and need to be custom coded in the FME workspace (e.g. validate that the correct coordinate system is being used; or that all features intersect an AOI). Parameters for these types of rules could easily be abstracted out to a rules table, to avoid the need for FME workspace updates once the initial development has been complete.
Putting it All Together
How the result of this type of validation is handled is, of course, up to the implementor but a common approach is to produce a report detailing any validation errors encountered so that they can be acted upon. The validation report can then be emailed to relevant stakeholders, either directly from within the FME workspace (using an Emailer transformer), or as part of a more robust notification system (e.g. FME Server) as described in Automated Data Validation Using FME.
Omitting error handling and reporting (for clarity), the final workspace might look something like this:
